写在前面:这里的提取是个人的提取(一些本人熟知的知识点不会在这里记录)。如果你也是新手级RoR选手,那这个提取能提供不少帮助。
开始:
- 程序语言有很多,各自目的不同:有的为了运行快速,有的为了一次编写,可以在从多平台使用,有的为了让小孩也能简单编程。而ruby:为了让编程更快乐!
- 什么是脚本语言:不需要经常翻译(编译),电脑能直接运行的语言。
第 1 部分 Ruby 初探
执行单个ruby文件
xxx.rb,方法:- 1ruby helloruby.rb
直接打开irb:
- 1$irb
\n是换行符。\:转义字符。程序会对这个
\后的字体做特殊的处理。1print("hello,\"ruby\".) #=> hello, "ruby".1print("hello \\ ruby!") #=> hello \ ruby!
""和'',单引号和双引号的区别:''里的东西,会原封不动地输出!(但,有两个符号除外:'&\)puts和print方法的区别:puts后面默认会带有换行符。print后面默认不带换行符。
p方法可以做什么:(这个方法一般是程序员在用!)- 能从输出结果分辨字符串与数值。
- 不会转义。
编码的规则称为
encoding用这条指令开启irb可以开启简洁模式:
1$irb --simple-prompt要用
sinsqrt等方法时,可以这样:(使用Math这个类方法)
|
|
注释:
单行注释:以
#开头的注释。多行注释:
1234=begin这是一个例子2017-7-5日=end还有一个作用:暂时不执行
while语句:12345i = 1while i <= 10puts ii = i + 1endtimes语句:(迭代器)1235.times dop "example"end像数组、散列这样保存对象的对象,我们称为容器(container)。
数组:
什么是数组: 按顺序保存多个对象的对象。
数组的大小 :
size12a = [1,2,3]a.size #=> 3
散列:
- 散列是键值对(key-value pair)的一种数据结构。
正则表达式:
什么正则表达式:
1/abc/ =~ "eacbcefg"- 左边:模式,用
/ /包起来。 - 右边:要匹配的字体串。
1/abc/i =~ "aAbcdefg"- 在
/后面加一个i表示忽略大小写。
- 左边:模式,用
从命令中拿到参数:
- 使用ruby内置的方法:
ARGV[X]就像数组一样用。 - 什么叫库:大部分的编程语言都提供了把多个不同程序组合为一个程序的功能。像这样,被其他程序引用的程序,我们称为库(library)。
require "./grep"中的./表示:当前目录下。pp方法和p的区别:pp可以适当地换行调整输出结果,让显示更漂亮。
第2部分 Ruby的基础:
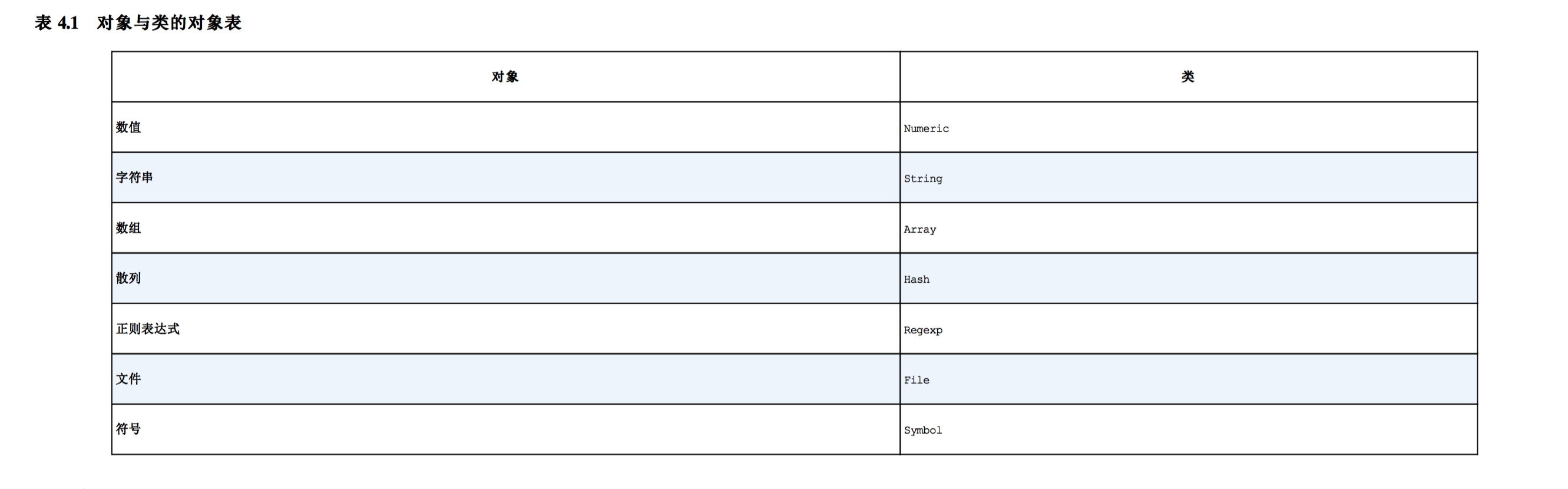
什么是对象:在RUBY中, 靓丽数据的基本单位称为对象。
- 数值对象
- 字符串对象
- 数组对象,散列对象
- 正则表达式对象
- 时间对象
- 文件对象
- 符号对象
什么是类:表示对象的种类。
什么是伪变量:代表某特定值的特殊量。
niltruefalseself
常量:
- 常量以大写英文字母开头。
- 给常量重复定义时,ruby会做出警告。
多重赋值里还可以这样用:
12ary = [1,2]a,b = ary #=> a=1, b=2比较值是否相等时,通常用
==,但如果要严谨一点的,就用eql?一些控制循环的语句:
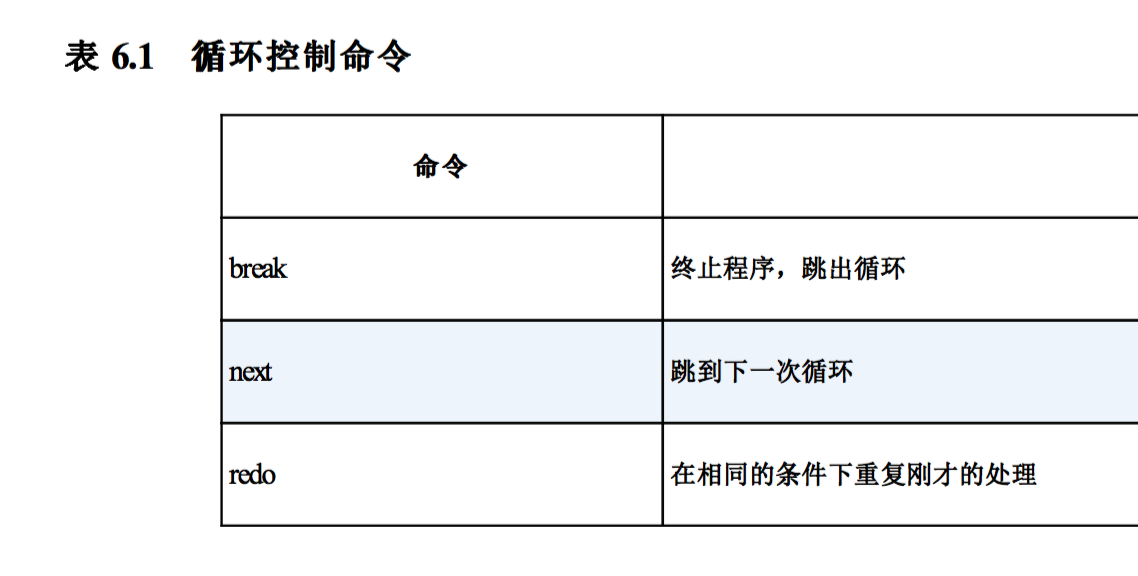
语法糖(syntaxsugar),是指一种为了照顾一般人习惯而产生的特殊语法
方法:
什么是方法:把一系统参数传递给对象的过程。(对象会返回结果值)
方法的调用:
1对象.方法名(参数1, 参数2, ..., 参数n)方法的分类:
实例方法:作用在实例上的方法。
类方法:作用在类上的方法。调用:
1类名.方法名1类名::方法名函数式方法:没有作用对象的方法,也没有回传值。
参数个数不确定的方法,使用带
*号的参数:这个参数组会被封装为数组供内部使用。
123456def foo(*args)argsendp foo(1,2,3) #=> [1,2,3]p foo(1,2) #=> [1,2]至少需要一个参数的方法:
123456def meth(arg, *args)[arg, args]endp meth(1) #=> [1, []]p meth(1,2,3) #=> [1, [2,3]]首尾确定,中间不确定时:
123456def a(a, *b, c)[a,b,c]endp a(1,2,3,4,5) #=> [1, [2,3,4], 5]p a(1,2) #=> [1, [], 2]关键字参数:以hash形式传递参数:
123def a(a: 1, b: 2, c: 3)[a,b,c]end如果想传递未定义的参数:
12345def a(a:1, **args)[a, args]endp a(a: 2, k: 3, v: 4) #=> [2, {:k => 3, :v => 4}]
类与模块:
判断某个对象是否属于某个类时:
instance_of?123456ary = []str = "Hello world."p ary.instance_of?(Array) #=> truep str.instance_of?(String) #=> truep ary.instance_of?(String) #=> falsep ary.instance_of?(Array) #=> false判断某个对象是否属于某个类时:
is_a?123str = "This is a String."p str.is_a?(String) #=> truep str.is_a?(Object) #=> true常量:
123class HelloWorldVersion = "1.0"end调用时:
1p HelloWorld::Version #=> "1.0"@@xxx:类变量,可以多次修改。限制访问级别:
public公开,外部可以访问。一般默认方法都是public的,但initialize方法除外。private内部使用。外部无法访问。protected同一类中可以使用。外部无法使用。
想知道一个类下有什么方法可以 被调用 ?
1类名.instance_methods为方法设置多个名字:
alias12alias 别名 原名alias :别名 :原名删除方法:
undef 方法名orundef :方法名什么是单例类:只为了个实体对象服务的类和方法。
模块:
使用方法:
模块名.方法名- 在类中
include 模块名, 然后就可以直接使用方法啦~
如果希望在外部可以用
模块名.方法名,你可以这样做:1module_function :hello如果想知道继承关系 ,可以使用:
ancestors这个方法,如果想知道父类,可以使用方法:superclass。调用时的优先级:
类本身=>引入的模块(最后引入模块的优先)=>父类- 重复引入,第二个引入的会被忽略。
extend方法:直接引入作用在对象上的模块。12345678910module Editiondef edition(n)"#{self}第#{n}版"endendstr = "Ruby 基础教程"str.extend(Edition) #=> 将模块 Mix-in 进对象p str.edtion(4) #=> "Ruby 基础教程第 4 版"也可以用
extend来代替继承:123class MyClassextend ClassMethodsend
.ceil:进位的意思,会把对象变成大一位的整数。1234a=3.23b=5.8a.ceil #=> 4b.ceil #=> 6
运算符:
一直以为
||就是or的意思(visual basic中的or),今天才发现,我错了:其实这两个符号不仅可以用在判断,还可以用在运算!!!
||:从左到右,返回第一个不为 fasle 或 nil 的值。
1a = false || nil || 2 || 3 #=> a = 2&&:返回最后一个真值(期间不能出现假值)。
12a = 1 && 2 && 3 && 4 #=> a = 4a = nil && false && 1 #=> a = nil||=:当为 false 或 nil 时,才进行赋值。(这可给变量赋予默认值 )1var ||= 1 #=> 当var为nil或false时,var = 1
范围运算符
succ可以返回一个:进位到下一位的值。121.succ #=> 2a.succ #=> b原来ruby本身有优先级运算符:
121 + 2 * 3 #=> 1 + (2 * 3) #=> 72 +3 < 5 + 4 #=> (2 + 3) < (5 + 4) #=> true还有一些没见过的运算符,刚开始还是老实用括号吧,哈哈!
异常处理与错误提示:
错误提示格式:
12文件名:行号:in 方法名:错误信息(异常类名)form 文件名:行号:in 方法名example:
12345> ruby test.rbtest.rb:2:in `initialize':No such file or directory - /no/file(Errno::ENOENT)form test.rb:2:in `open'form test.rb:2:in `foo'form test.rb:9:in `main'可以用这个格式来处理异常:
123456789begin可能会发生异常的处理rescue => 引用异常对象的变量发生异常时的处理sleep(10) #=> 等待10秒retry #=> 再执行一次begin下的程式ensure不管是否发生异常都希望执行的处理end这样不至于遇到错误时立即爆掉!!!
还可以:简化
123456789begin表达式 1rescue表达式 2end#=> 等同于下面这个:表达式1 rescue 表达式2还可以:再简化
- 如果该方法是一整个begin ~ end 包含,可以省略
beginend,可以直接用rescueensure
- 如果该方法是一整个begin ~ end 包含,可以省略
还可以指定需要捕捉的异常:

主动抛出异常
raise
书中没有给出例子!差评!
sort方法可以对数组进行排序:
<=>排序运算符,可以进行排序。数组里如果要按照长度来排序,可以:
123array = ["rails", "ruby", "fullstack"]array.sort{ |a, b| a.length <=> b.length }#=> ["ruby", "rails", "fullstack"]解说:先利用
sort让数组遍历两两相比较,再增加代码块!人才啊!要想把一段文字,直接切成一个个单词然后放入数组?可以这样:
|
|
upto把值按从小到大的顺序取出,这个是Integer#upto方法!判断使用方法时是否有带块?
1if block_given?在块中直接调用
breaknext等方法控制流程,会直接返回nil,如果想返回带参数,可以使用:break 0next 0
利用
Proc把代码块变成对象后,就可以直接用cell方法来直接使用啦~123456hello = Proc.new do |new|puts "Hello, #{name}."endhello.call("World") #=> Hello, World.hello.call("Ruby") #=> Hello, Ruby.传参数的时候 ,有一种参数叫做:
Proc参数是这样的:&block(要放在最后一个参数)判断是否有带block的另一个方法:
1if block #直接进行判断块变量的作用域:只在block中有效。如果跟局部变量同名,要小心赋值问题!
第三部分
数值类
一些方法:
返回商的整数:
x.quo(y)返回一个数组,[商,余数]:
x.divmod(y)Math模块你想得到的数学函数都在里面返回整数部分:
.floor返回100以内的随机数:
Random.rand(100)(比我以前学的VB方便太多了好嘛!)Integer的迭代方法:upto遍历downto遍历
以分数的形式存在:
Rational(1, 10)按
step迭代的方法:2到10,每次加3:
1232.step(10,3) do |i|p iend #=> 2, 5, 810到2,每次减3:
12310.step(2,-3) do |i|p iend #=> 10, 7, 4
数组:
Array.new方法:123Array.new #=> []Array.new(5) #=> [nil,nil,nil,nil,nil]Array.new(5,0) #=> [0,0,0,0,0]%w和%i创建不包含空白的字符串数组时,可以使用
%w:12lang = %w(Ruyb Perl Python Scheme Pike)p lang #=>["Ruby","Perl","Python","Scheme","Pike"]创建不包含空白的符号数组时,可以使用
%i:12lang = %w(Ruyb Perl Python Scheme Pike)p lang #=>[:Ruby,:Perl,:Python,:Scheme,:Pike]
其中
()可替换成其他符号:<>||!!@@AA将散列转换成数组:
12a = {a: 1, b: 2}a.to_a #=> [[:a, 1], [:b, 2]]一次性拿到多个值:
a[n]ora[-n]如果是负数,就倒着开始取值。超过总数值会报错。
a[n..m]ora[n…m]a[n,len]从某个元素起,取n个字符。
一次性赋多个值:
- 123a = [1,2,3,4,5,6]a[2,3] = [c,d,e] #=> [1,2,c,d,e,6]a[2,0] = [a,b] #=> [1,2,a,b,3,4,5,6]
- 12a = [1,2,3,4,5,6]a[2..3] = [a,b] #=> [1,2,a,b,5,6]
.values_at方法:12a = [1,2,3,4,5,6]a.values_at(1,3,5) #=> [2,4,6]
把数组当集合来运算:
交集:
ary = ary1 & ary2并集:
ary = ary1 | ary2集合的差:
ary = ary1 - ary2(在1中找2没有的元素)123ary1 = ["a","b","c"]ary2 = ["b","c","d"]p (ary1 - ary2) #=> ["a"]
把数组当列:
数组结构:
- 队列:以排列的顺序,先进先出。(像排队过关一样)
- 栈:以相反的顺序,先进后出。(像堆东西一样,最慢放入的最容易取出)
- 追加,删除,引用:
| 操作 | 在头部开刀 | 在尾部开刀 |
| :–: | :—–: | :—: |
| 追加元素 | unshift | push |
| 删除元素 | shift | pop |
| 引用元素 | first | last |例子:
1234a = [1,2,3,4,5]a.push("E") #=> [1,2,3,4,5,E]a.shift #=> 1a #=> [2,3,4,5,E]
一些操作方法:
为数组增加元素:
a.unshift(item)a.push(item) ~= a << itema.concat(b)&a+b这个
concat方法是破坏性方法,会改变被引用的对象。
什么是破坏性的方法?
:会改变接收对象值的方法!要注意:被引用的对象也会被破坏!如:
12345> a = [1,2,3,4]> b = a> b.pop #=> 4> p a #=> [1,2,3]>>
提示:这里b引用了a,并不是复制一个a,而是让a和b同时引用一个对象!这一点要纠正认识!
从数组中删除元素:
a.compact&a.compact!:会把a数组中的空元素nil去掉!区别:- 第一种会返回一个新的数组。
- 第二种会直接替换掉原来的数组。
a.delete(x):从数组中删除x元素。a.delete_at(n): 从数组中删除a[n]元素。a.delete_if {|item| … }a.reject {|item| … }a.reject! {|item| … }
: 这三个方法表示:遍历所有元素,如何右边的block块成立就删掉,其中带感叹号表示破坏性的方法!a.slice!(n)a.slice!(n..m)a.slice!K(n,len)
: 这三个方法表示:从数组a中删除指定的部分,并返回被删除的部分的值。slice!是具有破坏性的方法。a.uniq&a.uniq!:表示:去掉重复的元素。a.shift:删除开头的元素。返回删除的值。a.pop:删除末尾的元素。返回删除的值。
替换数组元素:
a.collect{|item| … }a.collect!{|item| … }a.map{|item| … }a.map!{|item| … }
: 遍历数组a和各元素传给block中的item,最后付出处理后的结果。a.fill(value)a.fill(value, begin)a.fill(value, begin, len)a.fill(value, n..m)
: 把数组指定元素全部替换成value,默认为全部。a.flatten&a.flatten!:平坦化数组a,就是把里面嵌套的数组展开成一个大数组。(soga,原来是这样啊!)123a = [1,[2,[3]],[4],5]a.flatten!p a #=> [1,2,3,4,5]a.reverse&a.reverse!:反转数组a的元素顺序。a.sorta.sort!a.sort {|i,j| … }a.sort {|i,j| … }
:排序,其中block中的i&j表示:从数组中两个两个拿出来的数据。a.sort_by{|i| … }:根据块的运行结果时序排序。12a = [2,4,3,5,1]p a.sort_by{|i| -i } #=> [5,4,3,2,1] (这里的block只是参与计算而已,不会破坏原来的数组。)
数组与迭代器:有些使用迭代器的对象不是数组,但处理后会返回一个数组:
123a = 1..5b = a.collect{|i| i += 2}p b #=> [3,4,5,6,7]数组的初始化问题:
12345a = Array.new(3, [0,0,0]) #=> [[0,0,0],[0,0,0],[0,0,0]]a[0][1] = 2 #=> [[0,2,0],[0,2,0],[0,2,0]]数组的初始化就是有这些问题,要注意,可以使用block带解决:a = Array.new(3) {[0,0,0])} #=> [[0,0,0],[0,0,0],[0,0,0]]a[0][1] = 2 #=> [[0,2,0],[0,0,0],[0,0,0]]zip方法:引进多个数组,然后同步遍历!:123456789ary1 = [1,2,3,4,5]ary2 = [10,20,30,40,50]ary3 = [100,200,300,400,500]result = []ary1.zip(ary2,ary3) do |a, b, c|result << a + b + cendp result #=> [111, 222, 333, 444, 555]一个过滤数组的方法:
.select12a = (1..100).to_aa.select{|i| i % 3 == 0} 过滤3的倍数。
13章练习题:
创建一个1到100的整数按升序排列的数组:
1(1..100).to_a累加1中的数组:
1a.reduce :+inject方法:12a.inject(0){|memo, i| memo += i}表示:遍历数组元素赋值给i,每次结果回传给memo.实现累加的效果。
字符串String
什么是内嵌表达式?
1"String#{ruby}" #=> 这个#{}里可以执行ruby表达式的东西就是啦!创建字符串
使用%Q与%q
1234desc = %Q{Ruby 的字符中也可以使用'' 和 "".}str = %q|Ruby said, 'Hello world!'|其中%Q相当于"",%q相当于''。Here Document方法
1234567<<"结束标识"内容结束标识#=> (这里更多的时候要换成<<-"结束标识",这样能让结束的标识不一定在)这个方法应该很少用。sprintf方法&printf方法printf
12345n = 123printf("%d\n", n) #=> %d表示以整数形式输出printf("%4d\n", n) #=> %4d表示以4位数格式输出printf("%04d\n", n) #=> %04d表示不够4位时被零printf("%+d\n", n) #=> %+d表示输出结果带 + or -1234n = "Ruby"printf("Hello,%s!\n",n) #=> %s表示以字符串形式输出printf("Hello,%8s!\n",n) #=> %8s表示输出炎8位字符串printf("Hello,%-8s!\n",n) #=> %-8s表示输出左对齐的8位字符sprintf
和
printf一样的结果。但书中没有说明具体区别,差评!
获取字符串的长度
lengthorsize两种方法可以,随意!bytesize可以获取字节数。- 判断是否为0:
empty?
字符串的索引
- 当成数组一样用就可以了。
连接字符串
用
+号123a = "Hello,"b = "World!"a + b #=> "Hello,World!"用
<<号123a = "Hello,"b = "World!"a << b #=> "Hello,World!" (a会被改变!)
字符串的比较
判断两个字符串是否相同:
==!=比较大小
1"aaaaa" < "b" #=> true 一般按照a~z的顺序排序如果查看
码位:.ord
字符串的分割:
split(x):以x为分割点进行分割!换行符的操作:
删掉
| 属性 | 删掉最的一个字符 | 删掉挑选符 |
| :—: | :——: | :—-: |
| 非破坏性的 | chop | chomp |
| 破坏性的 | chop! | chomp! |12345a = "abcde"b = "abcde\n"a.chop #=> "abcd"b.chop #=> "abcde"b.chomp #=> "abcde"
字符串的检索与置换
字符串的检索
index方法从左到右检索,返回第一个字母的索引rindex方法从右到左检索,返回第一字母的索引
123a = "abbbbbb"a.index("bb") #=> 1a.rindex("bb") #=> 5判断是否包含某个索引值:
include?12a = "abbbbbb"a.include?("bb") #=> true
字符串与数组有很多共同的索引的方法:
s[n]s[n..m]s.slice!(n)s.concat(s2)s+s2s.delete(str)s.reverse
其他方法:
strip: 删除头尾的空白字符upcase:小写转大写downcase:大写转小写swapcase:大的转小,小的转大capitalize:首字母大写,其余转小写tr:置换字符,与gsub相似,但这里可以一次转换多个字符。1"ABCDE".tr("BD", "bd") #=> "AbCdE"
14章节练习题提取:
一个打散的字符串数组,如何快速连接成句子:
123a = ["Ruby", "is", "an", "object", "oriented", "programming", "language"]a.join(" ")#=> "Ruby is an object oriented programming language"统计下面各个字母出现次数,并用*的个数来表示次数:
12345678a = "Ruby is an object oriented programming language"b = Hash.new(0)a.each_char do |c|b[c] += 1endb.sort.each do |k, v|printf("'%s': %s\n", c, "*" * v.to_i)end运行结果如图:
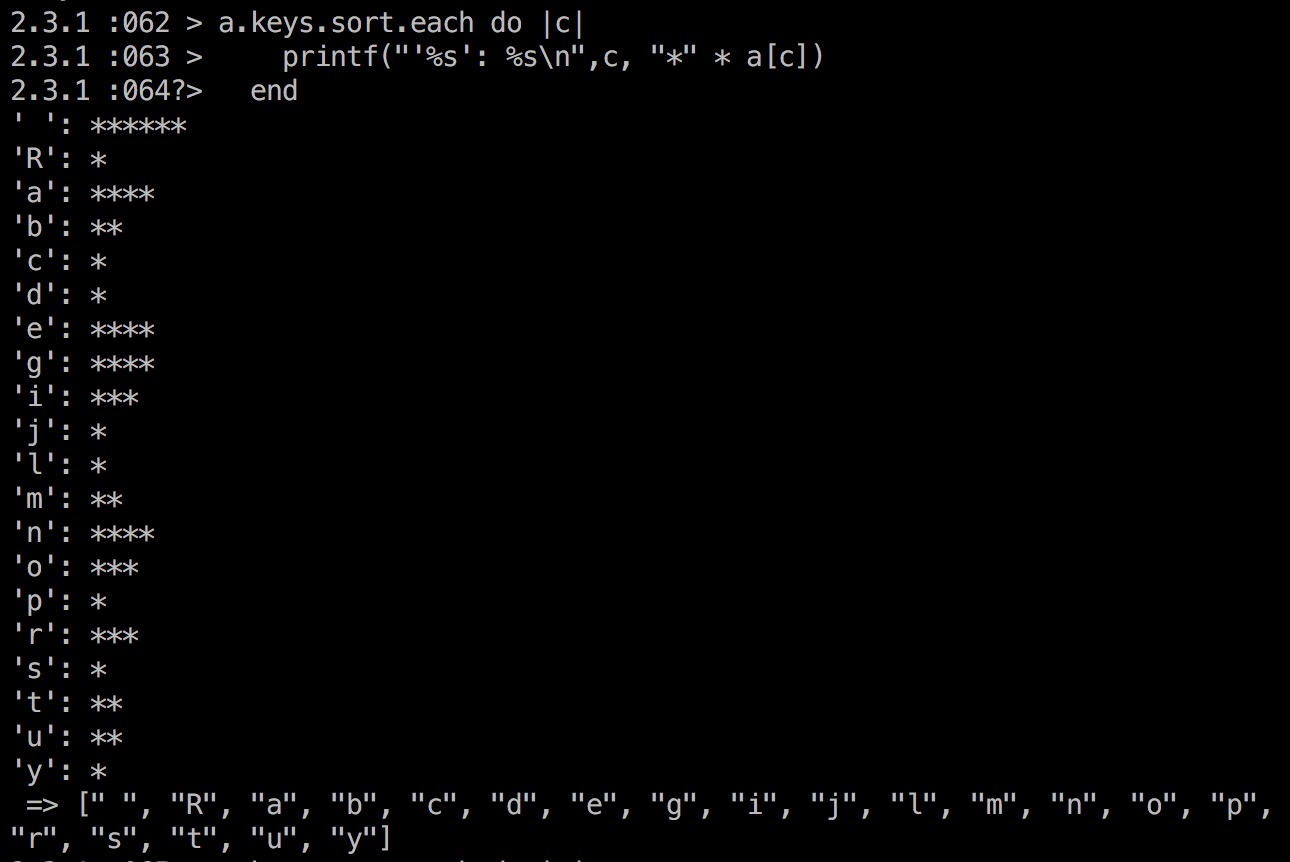
很酷!
- 散列直接用
a[c]就可以拿到这个值,不需要进行检索 printf格式输出,方便!先定义好整个字符串样式,再后面定义各个引用值。
- 散列直接用
散列类
新建hash:
a = {}a = {键: 值}a = Hash.new(x)(这里可以设置一个默认值)。
值的获取与设定
fetch&store一个用来取一个用来存,基本和a["s"]的作法一样,但:用下面两个方法可以
- 设默认值
- 添加block
123a.store("s1", "Ruby")a.fetch("s2", "undef") #=> "undef" (找不到,所以默认值)a.fetch("s2"){String.new} #=> "" (这里还可以用block)
hash的迭代器。
| 数组形式 | 迭代器形式 |
| :—-: | :——————-: |
| keys | each_key{|键| …… } |
| Values | each_value{|值| …… } |
| to_a | each{|键,值| …… } |
| | each{|数组| …… } |hash的默认值。好处:取不存在的值时,不至于发生错误。
创建hash时指定默认值:
1234h = Hash.new(1)h["a"] = 10h["a"] #=> 10h["b"] #=> 1创建hash时增加一个block:
1234567h = Hash.new do |hash,key|hash[key] = key.upcaseendh ["a"] = "b"p h["a"] #=> "b"p h["b"] #=> "B"p h["c"] #=> "C" 当找不到这个值时,就会自动去执行这个block用fetch方法指定默认值:
12345h = Hash.new do |hash.key|hash[key] = key.upcaseendp h.fetch("x", "(undef)") #=> "(undef)"同时两个默认值的方法,fetch的优级级会高
判断是否为某个Hash的
键or值- 键
h.key?(key)h.has_key?(key)h.include?(key)h.member?(key)
- 值
h.value?(value)h.has_value?(value)
- 键
查看Hash的大小
h.size&h.length12h = {"a" => "b", "c" => "d"}h.size #=> 2h.empty?
删除值:
h.delete(key)h.delete_if{|key, val| … }h.reject!{|key, val| … }当不符合时,
delete_if会返回原来的Hash,reject!会返回一个nil
初始化散列
h.clear清空使用过的散列那这个东西和
h = Hash.new有什么区别呢?在引用的时候要注意下,请看图: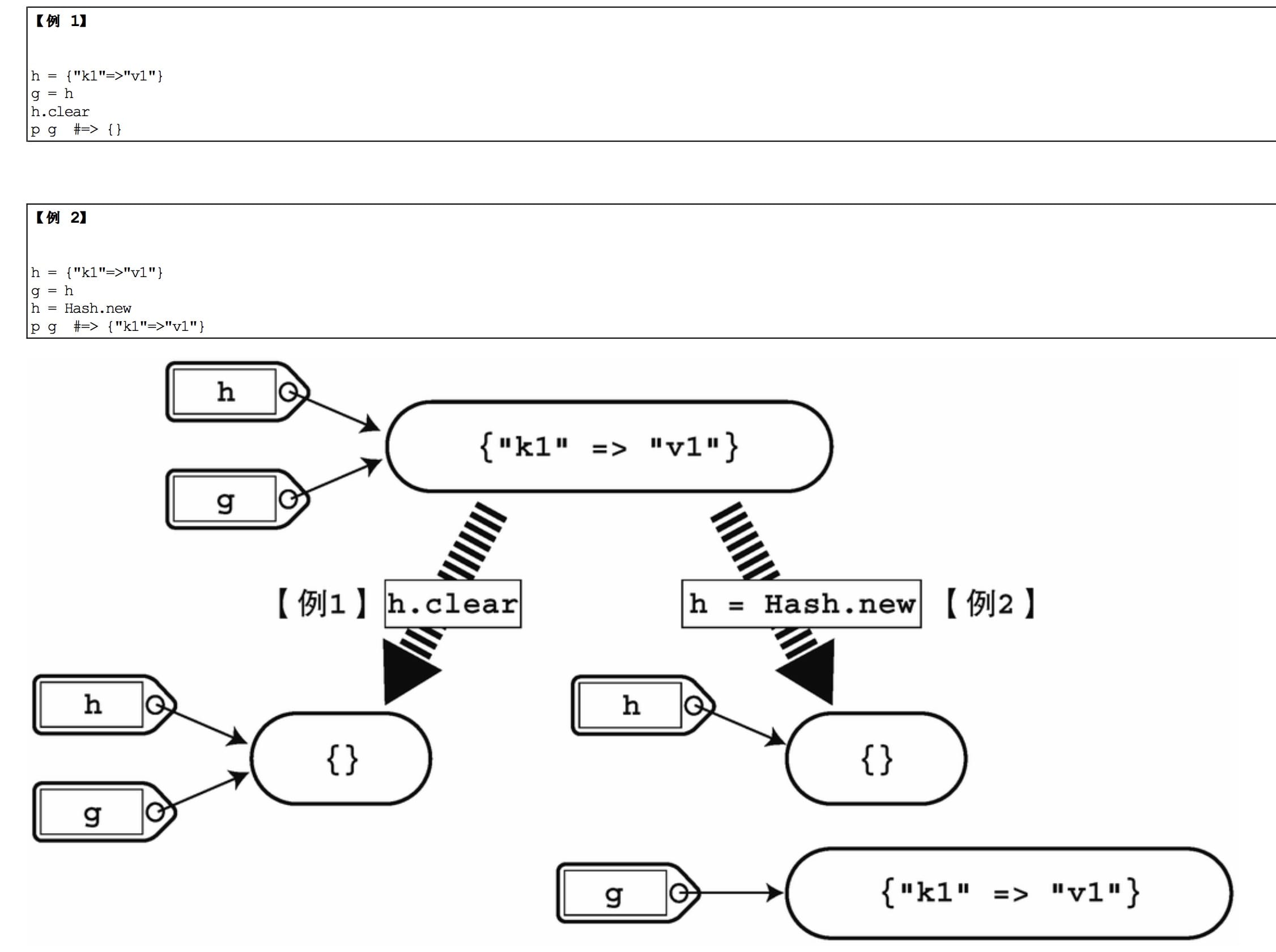
我忘记了一个超级方便的排序方法:
sort
PS:比起之学VB时的什么泡沫排序法之类的,这里简直不能太好!
正在表达式(Regexp类)
正则表达式的创建:
1re = Regexp.new("Ruby") #=> /Ruby/%r(模式)%r<模式>%r|模式|%r!模式!
判断某个字符串是否匹配:
正则表达式 =~ 字符串匹配:返回匹配的起始位置
不匹配:返回nil
还可以:用
!~来颠倒结果。进一步应用:
12345if 正则表达式 =~ 字符串匹配时的处理else不匹配时的处理end
匹配行首与行尾:
^, $分别表示匹配行首与行尾:像这样的特殊字符称为:元字符。
\A,\z分别表示匹配字符串头与尾:\z\Z两者的区别123> p "abc\n".gsub(/\z/, "!") => "abc\n!"> p "abc\n".gsub(/\Z/, "!") => "abc!\n!">>
:大写的
\Z,如果最后一个是换行符,则会同时匹配换行符与前一个字符。匹配某一个字符:
[AB]:匹配A 或B[ABC]:匹配A,B,C中的一个[012ABC]:匹配0,1,2,A,B,C中的一个[A-Z]:匹配A~Z中的一个[ABC][BC]: 匹配一个两位数,第一个数为A,B,C中的一个,第二位数为B,C中的一个。[A_-]:匹配A_-中的一个。[^ABC]:匹配除A,B,C外的任意一位数。.:万能通配符,相当于五笔中的z
反斜杠模式
\s: 匹配空格,制表符, 换行符,换页符\d:匹配0到9的数字。\w:匹配英文字与数字。\A:匹配字符串的开头。\z:匹配字符串的末尾。\:后面如果跟着:^$[等字符时,可以为这些字符转义再匹配。如:| 模式 | 字符串 | 匹配部分 |
| ——- | ——— | ———— |
| /ABC[/ | “ABC[“ | “▶ ABC[ ◀” |
| /\^ABC/ | “ABC” | (不匹配) |
| /\^ABC/ | “012^ABC” | “012▶^ABC ◀” |
重复模式:(单个字符)
*:重复0次以上。可以重复很多次也可以直接没有+:重复1次以上。至少有一次以上?:重复0次或1次。可有可无不重复,前后的匹配还是要的!
最短匹配:
上面6中和重复匹配会最可能匹配更多的字符。
最短匹配:加上一个
?,在第一次匹配时就停止,匹配最短的字符。也叫贪婪匹配与懒惰匹配。
使用
()来重复匹配多个字符。| 模式 | 字符串 | 匹配部分 |
| ———- | ———- | ———– |
| /^(ABC)$/ | “ABC” | “▶ABC ◀” |
| /^(ABC)$/ | “” | “▶◀” |
| /^(ABC)$/ | “ABCABC” | “▶ABCABC ◀” |
| /^(ABC)$/ | “ABCABCAB” | (不匹配) |使用
|来多一个匹配选项,可以多选一,也可以全中。| 模式 | 字符串 | 匹配部分 |
| ————– | —– | ——– |
| /^(ABC|DEF)$/ | “ABC” | “▶ABC ◀” |
| /^(ABC|DEF)$/ | “DEF” | “▶DEF ◀” |
| /^(ABC|DEF)$/ | “AB” | (不匹配) |使用
quote方法来转义所有表达式所有字符:
|
|
正则表达式的一些选项:
形式:
/ … / imi:忽略英文有大小写x:忽略正则表达式中的空白字符以及 # 后面的字符的选项。指定这个选项后,我们就可以使用 # 在正则表达式中写注释了。m:使用后可以:用.匹配换行符了。
捕获:
查看匹配的部分是什么字符串:以
()的形式1234567/(.)(.)(.)/ =~ "abc"first = $1second = $2third = $3p first #=> "a"p second #=> "b"p third #=> "c"如果是有重复的匹配只会捕获最后一次的字符,如果此时我们想忽略它的捕获,可以这样:以
(?:)开头就可以忽略捕获。1234567/(.)(\d\d)+(.)/ =~ "123456"p$1 #=> "1"p$2 #=> "45"p$3 #=> "6"/(.)(?:\d\d)+(.)/ =~ "123456"p $1 #=> "1"p $2 #=> "6"另外一种形式:
12345/C./ =~ "ABCDEF"p $` #=> "AB"p $& #=> "CD"p $' #=> "EF"这三种可以捕获整个匹配过程的字符
sub方法与gsub方法:带block
123456789str = "abracatabra"nstr = str.sub(/.a/) do |matched|'<'+matched.upcase+'>'endp nstr #=> "ab<RA>catabra"nstr = str.gsub(/.a/) do |matched|'<'+matched.upcase+'>'endp nstr #=> "ab<RA><CA><TA>b<RA>"可以带block,然后把匹配的部分传入block,最后block处理后的结果置换匹配的字符串。
直接返回的字符串数组:
scan方法1p "abracatabra".scan(/.a/) #=> ["ra", "ca", "ta", "ra"]
这是纠正一点:转义符号增加的顺序:
>
纠正:
\+要转义的符号这才是正确的格式。
章节:IO类
这一章节主要对文件内容的操作。暂时不会用到,理解起来也费劲。
章节:File类与Dir类
这一章节主要是对文件夹的操作。暂时不会用到,记起来也很费劲。
章节:Encoding类
这一章节主要是编码类的讲解。暂时不会用到,要用到时再来查看。
第20章 Time类与Date类
获取当前时间:
Time.newTime.now
时间相关的方法:
| 方法名 | 意义 |
| —– | ———————— |
| year | 年 |
| month | 月 |
| day | 日 |
| hour | 时 |
| min | 分 |
| sec | 秒 |
| usec |秒以下的位数(以毫秒为单位)|
| to_i | 从 1970 年 1 月 1 日到当前时间的秒数 |
| wday | 一周中的第几天(0 表示星期天) |
| mday | 一个月中的第几天(与 day 方法一样) |
| yday | 一年中的第几天(1 表示 1 月 1 日) |
| zone | 时区(JST 等) |指定特定时间:
12t = Time.mktime(2017,7,25,16.59,40)#=> 2017-07-25 16:40:00 +0800时间的比较:
<>-等,平常的计算比较方法都可以用啦。
时间的计算:默认直接计算秒数:
123t = Time.nowp t #=> 2013-03-30 03:11:44 +0900 t2=t+60*60*24 #=>增加24小时的秒数p t2 #=> 2013-03-31 03:11:44 +0900时间输出的格式:
t.strftime(format)t.to_s
| 格式 | 意义与范围 |
| —- | ——————————– |
| %A | 星期的名称(Sunday 、 Monday ……) |
| %a | 星期的缩写名称(Sun 、 Mon ……) |
| %B | 月份的名称(January 、 February ……) |
| %b | 月份的缩写(Jan 、 Feb ……) |
| %c | 日期与时间 |
| %d | 日(01 ~ 31) |
| %H | 24 小时制(00 ~ 23) |
| %I | 12 小时制(01 ~ 12) |
| %j | 一年中的天(001 ~ 366) |
| %M | 分(00 ~ 59) |
| %m | 表示月的数字(01 ~ 12) |
| %p | 上午或下午(AM、PM) |
| %S | 秒(00 ~ 60) |
| %U | 表示周的数字。以星期天为一周的开始(00 ~ 53) |
| %W | 表示周的数字。以星期一为一周的开始(00 ~ 53) |
| %w | 表示星期的数字。0 表示星期天(0 ~ 6) |
| %X | 时间 |
| %x | 日期 |
| %Y | 表示西历的数字 |
| %y | 西历的后两位(00 ~ 99) |
| %Z | 时区( JST 等) |
| %z | 时区(+0900 等) |
| %% | 原封不动地输出 % |示例:
12t = Time.now.strftime("%Y-%m-%d")#=> "2017-7-25"另外两个冷门的格式:(需要引用time类)
t.rfc2822t.iso8601f
1234require "time"t = Time.nowp t.rfc2822 #=> "Tue, 25 Jul 2017 17:19:00 +0800"p t.iso8601 #=> "2017-07-25T17:19:42+08:00"本地时间与国际时间的切换:
t.utct.localtime
1234t = Time.nowp t #=> 2017-07-25 17:21:35 +0800t.utc #=> 2017-07-25 09:21:35 UTCt.localtime #=> 2017-07-25 17:21:35 +0800从字符串中获取时间:
Time.parse(str)123require "time"p Time.parse("2017-7-25") #=> 2017-07-25 00:00:00 +0800
日期的获取:Date类,适合只需日期不需时间的操作。
Date.today计算:直接加减默认计算天数
同样也有各种方法:
12345678d = Date.todayp d.year pd.month pd.dayp d.wday p d.mday pd.yday# 年 => 2017#月 => 7#日 => 25# 一周中的第几天(0 表示星期天)# 一个月中的第几天(与 day 方法一样) => 30 #一年中的第几天(1表示 1月 1日) =>206用指定日期生成Date对象:
12d = Date.new(2017,7,25)puts d #=> 2017-7-25还可以用
-1-2表示末尾的第几天:123> d = Date.new(2017,7,-1) #=> 2017-7-31 7月月尾> d = Date.new(2017,7,-2) #=> 2017-7-30 7月月尾前一天>
Date类的运算:
- 正常的加减,默认会以天数为单位计算
>><<会以月份为单位进行运算。
Date类的格式:
- 与前面的Time类一致。
- 从字符串中获取Date类:
- 和Time类一致:
Date.parse(str)
- 和Time类一致:
Proc类
什么是proc类,
把block块变成一个对象,这个对象所属的类就是Proc类。这样可以方便我们在后面的调用。
创建方法:
Proc.new(…)proc{}
调用方法:
利用
Proc#call方法利用
Proc[]方法123456sayhello = Proc.new do |name|puts "Hello, #{name}."endsayhello.call("World") #=> Hello, World.sayhello["World"] #=> Hello, World.
另一种写法:
lambdalambda还有另外一种写法:-> (块变量){处理}123456789prc1 = Proc.new do |a, b, c|p [a, b, c]endprc1.call(1,2) #=> [1, 2, nil]prc2 = lambda do |a, b, c|p [a, b, c]endprc2.call(1,2) #=> 错误 (ArgumentError)lambdaproc两者的区别:- lambda的参数数量要对应否则会出错,proc的参数数量则没有那么严格。
- lambda可以使用return将值从块中返回。
proc类可以接收块
proc的特征:
具有闭包的特征。 闭包:将处理内容、变量等环境同时进行保存的对象,在编程语言中称为闭包(closure)。
proc的实例方法:
prc.call(args,…)prc[args, … ]prc.yield(args, … )prc.(args, … )prc === arg
123456prc = Proc.new{|a, b| a + b}p prc.call(1, 2) #=> 3p prc[3, 4] #=> 7p prc.yield(5, 6) #=> 11p prc.(7, 8) #=> 15p prc === [9, 10] #=> 19123456789101112fizz = proc{|n| n % 3 == 0 }buzz = proc{|n| n % 5 == 0 }fizzbuzz = proc{|n| n % 3 == 0 && n % 5 == 0}(1..100).each do |i|case iwhen fizzbuzz then puts "Fizz Buzz"when fizz then puts "Fizz"when buzz then puts "Buzz"elseputs iendendprc.arity: 返回块变量的个数。prc.parameters